
スクレイピング(スプレッドシート版)
スプレッドシートによるサイトの要素を取得する方法
スプレッドシートの関数を使いスクレイピング(サイトの情報を取得)します。
取得する要素として、タイトル、ディスクリプション等のメタタグ、ページ内の要素の取得を行います。
スクレイピング出来る関数には「IMPORTXML」、「IMPORTHTML」、「IMPORTDATA」、「IMPORTFEED」とありますが、今回は「IMPORTXML」、「IMPORTDATA」を使用し例を挙げて進めます。
ただ、悲しい事に完全無欠なスクレイピングを目指したい場合、スプレッドシートの関数では限界がありますので取得対象のサイト、取得状況、用途を考慮して選定して下さい。
- 準備するもの
- 要素を取得したいページのURL
- Googleアカウント
スプレッドシートを開く
googleへログインし、スプレッドシートを開きます。
右下の+ボタンより、新しいスプレッドシートを作成します。
取得したいサイト情報
取得したいページのURLをセルに貼り付けてください。
例として気象庁のページから取得を行ってみます。
http://www.jma.go.jp/jma/index.html
次に、「head」タグ内の、「title」、「description」、「keywords」を取得する関数を入力します。
使用する関数は「IMPORTXML」です。
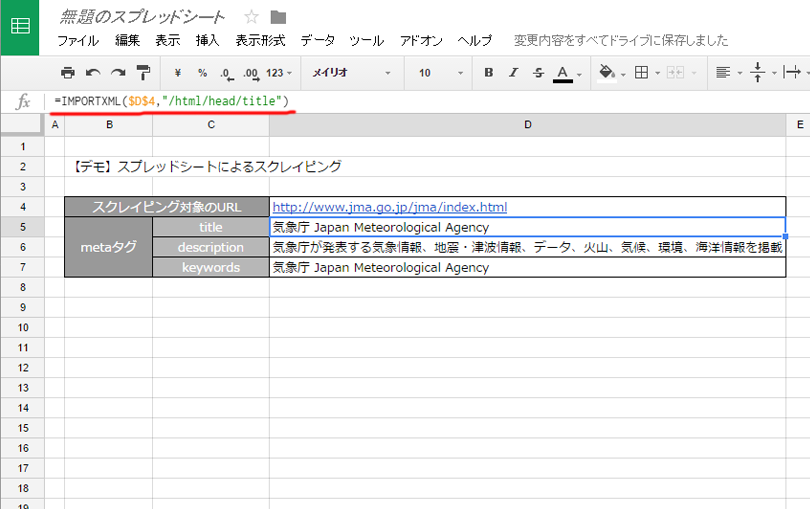
対象のURLのセルが「D4」の場合、下記の様になります。
■title
=IMPORTXML($D$4,"/html/head/title")
■description
=IMPORTXML($D$4,"/html/head/meta[@name='description']/@content")
■keywords
=IMPORTXML($D$4,"/html/head/meta[@name='keywords']/@content")
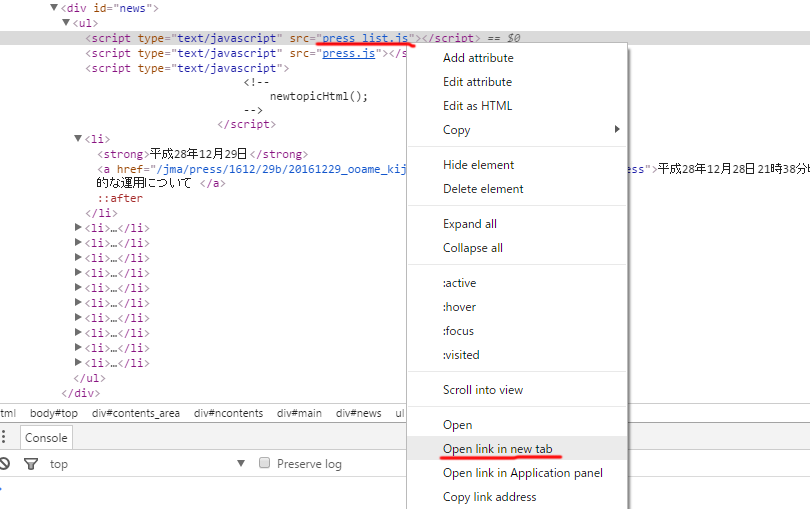
関数の第二引数が、なんだかヤヤコシイと感じた方はブラウザのデベロッパーツールで「Xpathの取得」が割と簡単に入手をお勧めいたします。※IDの指定部分等ダブルクォーテーション「”」がある場合シングルクォーテーション「’」に修正してください。
(サイトによって細かい調整が必要になる場合があります。)
※第二引数の説明
- IDで取得したい場合・・・「//*[@id=’logo’]」
- 属性で取得したい場合(例として画像のalt)・・・「//*/img/@alt」
- 順番で取得したい場合・・・「//*/div[1]」
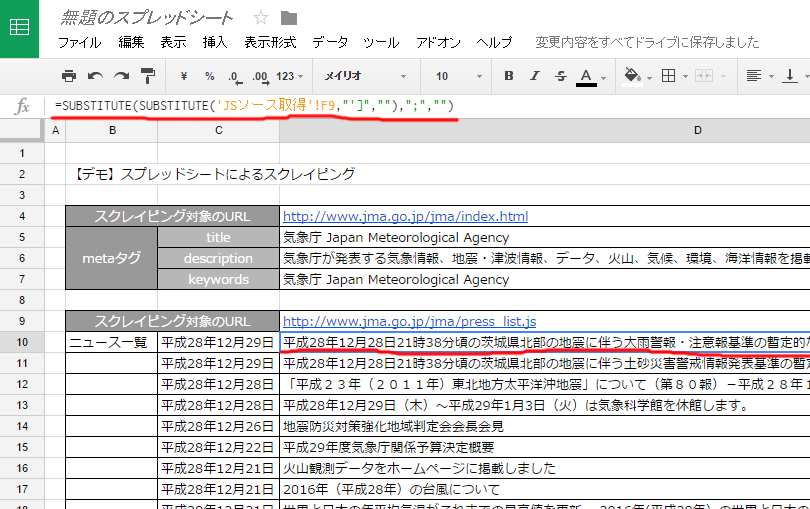
【上記までのイメージ】
※注意
上記でも取得できない場合があります。
サーバーサイドで構成されたタグであれば取得が可能ですが、jsの「document.write」でHTMLを生成している場合取得ができない場合がそれに当てはまります。

JSのソースコードの記述を取得する
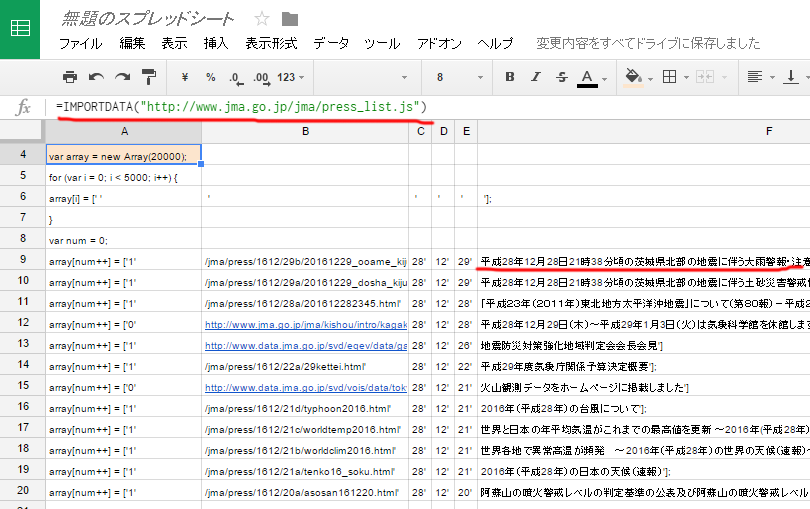
jsの「document.write」の場合は「IMPORTDATA」を使い取得を試みます。
ほぼ「IMPORTXML」と同様です、第一引数はjsを参照させます。
※第二引数については省略します。表示書式や、取得するjs、csvの文字区切りに関係している様です。
余談ですが、不要な文字が入っている場合、「SUBSTITUTE」の関数を使うと便利でした。
jsの記述について、全てが外部ファイルではありません。
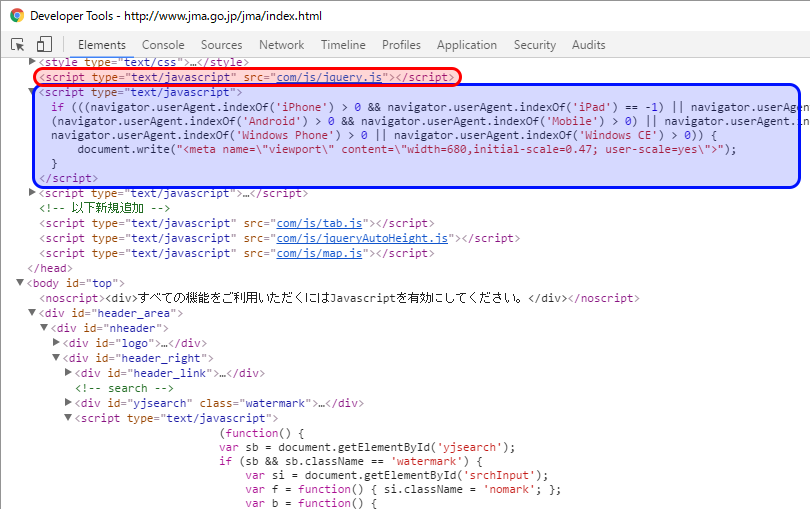
そういう場合は、「@src」、「text()」と出し分けます。
関数の例を下記に記載します。
=IF(ISERROR( IMPORTXML($D$4,"//*/script[" & C52 & "][@type='text/javascript']/@src")), IMPORTXML($D$4,"//*/script[" & C52 & "][@type='text/javascript']/text()"), IMPORTXML($D$4,"//*/script[" & C52 & "][@type='text/javascript']/@src") )
※すこし込み入った関数になったので内容内訳を明記
・外部ファイルとして読み込み読めるか判別する
・外部ファイルとして読み込めないので、べた書きのJSを出力する
・外部ファイルとして読み込めたのでファイル名を出力する
これでタイトル、ディスクリプション、キーワードのメタタグ、ページ内の要素(ニュースの一覧)を取得ができました。
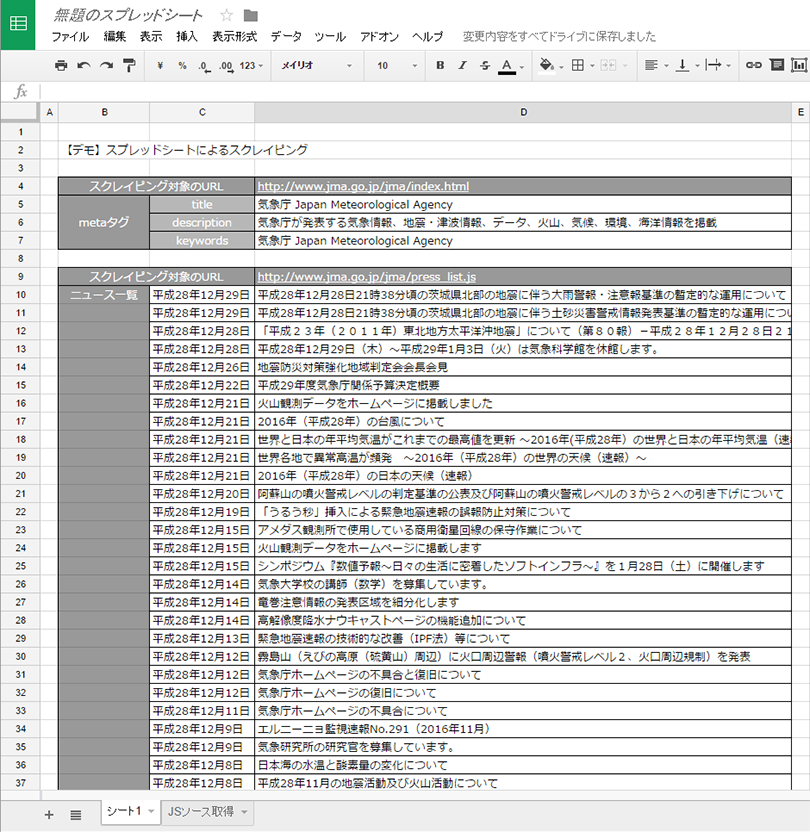
これにて完了とします。
別途、使う機会があれば「IMPORTHTML」、「IMPORTFEED」の関数も纏めたいと思います。
")
の結果")

